




编者按:本文来自微信公众号 王智远(ID:Z201440),作者:王智远,创业邦经授权转载。
前两天,有个威廉希尔中文网站 新闻传到了国内。
地址在加利福尼亚州旧金山,日期是7月16日。一个专门研究如何在人工智能时代改进搜索的实验室,Exa,宣布:共计融到2200万美元。
这笔钱Lightspeed Venture Partners带头。还有英伟达(NVIDIA)的风险投资部门和Y Combinator也参与投资;目的是帮助Exa快速发展,打造一个全新的搜索引擎,专门服务于人工智能。
什么?帮助人工智能,打造全新搜索?是的,你没听错。他们要给人工智能加个“外脑”,或者说,在搜索功能上加点新东西,让AI搜索更强进。
这让我很好奇,Exa到底是个什么样的公司?有什么特别的技术?创始团队背景是怎样的?为什么这么多资本投他们?
带着问题,我进行一番探索,发现一些不同的线索。
01
首先,你可能不信,Exa创始人很年轻,思想很前卫。
首席执行官Will Bryk现在27岁,联合创始人Jeff Wang才26岁。 不过,你可能会惊讶,这两位好朋友在ChatGPT推出之前就已经创办了这家公司。
那么,这家公司是做什么的呢?
Exa公司位于旧金山,是Cerebral Valley AI社区的一部分。这是一个国外专注于人工智能、机器学习、自然语言处理和数据科学的社区。
最开始,Exa构建一个工具,这个工具能让人工智能模型做类似网络搜索的事情。 这主要包括了从互联网上查找信息,以及帮助客户回答问题的人工智能聊天机器人,还有一些公司希望用来策划培训数据。
创始人早些年花100万美元买了GPU,他们使用矢量数据库和嵌入技术(这不是基于经典Transformer的大型语言模型),开始建立一个机器学习模型,模型被训练来本能地理解链接,而不是单个的词或句子。
Exa公司的创始人Will Bryk,解释了他们的搜索引擎和普通搜索引擎有什么不一样。他说:
通常AI搜索,像变形金刚,会猜你接下来可能会说什么单词 ;但他们的搜索引擎不是猜单词,而是猜链接,也就是你浏览网页时可能会点开的下一个网址。
我们是看大家在网上分享什么链接,来训练搜索引擎,所以,是一种全新的方式,不同于一般的搜索引擎只根据关键词来找东西。
就像大型语言模型通过提供最有可能的下一个单词来完成句子一样,Exa的系统会提供最有可能的链接(可能是十个)。 但是,你不会在里面看到像在普通搜索引擎中那样的搜索引擎优化的垃圾信息,或者那些讽刺的、由人工智能生成的无用内容。
Jeff Wang说:
公司最初目标不是为了服务人工智能,而是,想探索怎样利用人工智能来打造更好的搜索。
Exa之前有一个免费版本,允许任何人有限地尝试使用我们的搜索引擎,除此之外,还有几个不同等级的付费服务。这样,Exa能赚一些钱,除了运行自己的 GPU 集群外,Exa 的产品托管在 AWS 上。
结果,当ChatGPT爆火之后,很多人工智能公司开始向Exa请求他们的搜索引擎API版本,以便能将用到自己的模型中去。
之后事情就一发不可收拾了,现在已经有数千名开发者在使用我们的产品,客户也越来越多,从那以后,Exa获得了极大的关注。
例如:
Databricks就是Exa的一个大客户,它主要用Exa来为自己的模型培训计划寻找大型的训练数据集。
不难看出,这家公司并不像谷歌、Perplexity这样基因的公司,它们专注开发针对人工智能需求的技术,一开始用户群体是B端、针对AI搜索创业有需求的团队。
那么,Exa公司的创立的原因是什么呢?
创始人们对现在的互联网环境很不满意。他们觉得,互联网本来是个找信息很方便的好地方,现在因为大家争抢注意力变得越来越商业化,也变得扭曲了。
尤其是谷歌搜索,在谷歌,有一整个行业叫做搜索引擎优化(SEO)。这个行业目的,是用各种技巧让网页在搜索结果里排名靠前,这样就能吸引更多人的注意。
结果就是,哪怕你只是简单地想知道“感冒了怎么办?”你也会看到一大堆网站在争抢排名,而不是真的提供最有用的信息。
02
嗯,的确是不错的想法。我带着好奇也进行了测试。
打开官网,映入眼帘的几个英文:The web, organized(AI的搜索引擎), 显然,搜索引擎不只是为个人使用,更多是为AI搜索服务的;实际上个人也可以用。
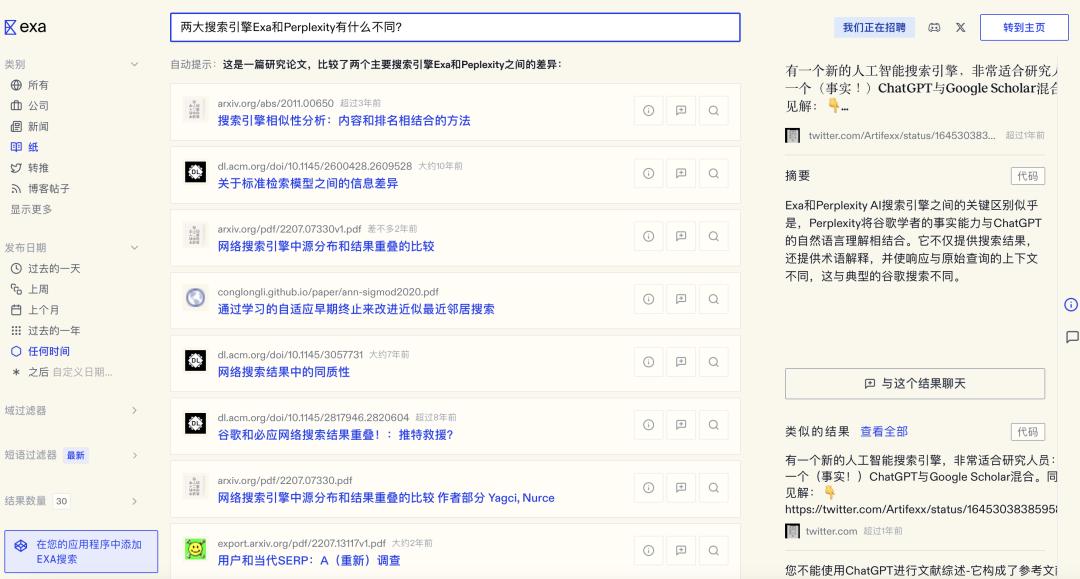
我搜的第一个问题是:Exa和Perplexity有什么不同?
它并没有像其他AI搜索软件那样,直接给我答案,而是展示一堆列表;在Exa的搜索结果里,左侧有固定类别的分类,我可以按照PDF、GitHub、公司、新闻、纸媒、推文、播客帖子等来筛选信息源。
当我点击“公司”类别后,就能看到来自各种公司网站的相关信息。
比如:
它给我显示一条9个月前Perplexity官网的帮助文档。点进去后,里面有关于Perplexity的介绍,说Perplexity是获取信息的最快方式,是一个工具,能让全世界的人用自己的语言或在自己的水平上学习任何东西。
我也可以不点进去,直接把鼠标悬停在标题上,右侧就会出现一个摘要,自动形成一个总结文档。 我还可以直接与这个文档进行交流。和其他AI搜索一样,下面还推荐了几个相关问题。
图释:(Exa官网搜索截图)
进行多轮测试,可以肯定,只要点击“新闻”,显示出来的都是引用自各大媒体的报道,比如华尔街新闻、TechCrunch等。
如果想看博客帖子,点击这一栏后,显示的是社区论坛博主们的思考,有来自于知名平台的,也有来自个人网站的。我随机点击几个,发现博主们内容质量很高,几乎都是各垂直领域的专家。
此外,Exa还可以按一天、一周、一个月、过去一年或任何时间筛选信息源的发布时间。
它还增加了域过滤器和短语过滤器:
域过滤器可以限定搜索范围,只在特定的文档字段或域中进行搜索,这可以提高搜索的精确度和效率。
短语过滤器,则用于处理和匹配特定的词组或短语,它会考虑词序和词之间的距离,确保搜索结果,更精确地匹配用户的查询意图。
不过,一个缺点是并没有给我直接的答案。可能是因为关于Exa的报道本身就较少,所以它没法自己创造内容。
这真的很技术思维,并不像谷歌、Perplexity用户体验感那么强。
我也遇到一个问题,当我搜“IPD是什么”时,它没有给我想要的答案。我意识到问题太过简单,于是我重新提问,加上IPD(Integrated Product Development集成产品完整表达,它才给我过滤掉那些和我意图不一样的内容。
它的索引能力真的很强。
9年前、16年前的内容都可以给我找出来,这些内容也并非完全可以使用,点进去看,明显有些逊色,而且居然有一些是卖书、卖专栏的产品广告,它们在广告中加了IPD方面的内容,外加上网站权重比较高,就被索引出来了。
据此,从个人使用感受来看:Exa的优点在于:
一,找资料利器,索引能力强、筛选条件多,非常适合技术人员使用,不适合小白用户。
二,还原过程指标,把结论放在单篇文章上,而不是一个问题上。缺点则是:一,无法给出直接答案,我一个个筛选信息源,点击查看;二,有些信息源不准确,这可能和我选择的筛选条件有关。
03
紧接着,我又拿Perplexity进行测试。Perplexity更友好。
从Perplexity的介绍里,我可以明白:
Exa主要为AI系统和开发者设计,它的工作给AI提供需要的知识和数据。而Perplexity则是给普通人用的搜索引擎,提供问答式的搜索体验,所以,这两个是完全不同的产品。
除此外,Exa定位为AI搜索的 中间层 ,提供API服务,整合世界知识为AI系统提供数据,Perplexity是一个端到端的搜索引擎,直接给用户提供摘要。
我详细查阅了一下, Exa使用Embedding技术来理解语义 ,能搜索Twitter、GitHub、Reddit等多种数据源; 而Perplexity则采用GPT-4o API和Claude-3、Sonar Large (LLaMa 3)等语言模型。
那么,它们二者有什么区别呢?
你可以想象一下,你有一堆玩具,每个玩具都有它的名字,比如“小汽车、洋娃娃、积木”。现在,要把这些玩具的名字告诉一台机器,让机器理解并记住它们。但问题是,机器不懂我们的语言,它只懂数字。
怎么办?
Embedding技术像一个魔法转换器,它可以把“小汽车”这样的名字变成一串数字,比如[1, 2],把“洋娃娃”变成另一串数字,比如[2, 3]。
这样,每个玩具的名字就都对应一串数字,机器就能通过数字来“理解”和区分不同的玩具了。
更神奇的是,这个技术还可以让相似的玩具有相近的数字。比如,“小汽车和卡车”可能都是车,所以它们的数字会比较接近,而和“洋娃娃”的数字就会远一些。
所以,Embedding技术,是帮助机器通过数字来理解和记住各种信息的一种方法。
而GPT-4o API和Claude-3不一样,它们本意上是已经被开发好的一个语言模型,Perplexity只是把不同的模型整合起来,去做写文章、回答问题、聊天的动作。
所以,很明显,Embedding技术和GPT-4o API、Claude-3的最主要区别是:
前者能把词汇、图片等变成一串数字,这样更容易让计算机学习和使用;后者更贴近用户,帮助我在网上找到你需要的信息,比如新闻、图片或视频等。
因此,我们可以得到一个结论:Exa是一个为AI和开发者服务的高级搜索工具,它更注重于数据的深度整合和技术处理;Perplexity是面向普通用户的搜索引擎,注重直接好用的便捷性,两者不是一个赛道。
04
关于Embedding技术,中国也有不少研究者在讨论。
我查了一下:
百度智能云的一篇文档里,深入讨论了Embedding技术在推荐系统中的应用。
这包括怎样更好地推荐用户和商品,还有序列推荐和知识图谱的应用。这些技术把零散的数据变成连续的向量(就像一串串数字),提高了推荐系统的表现和准确度。
还有一个技术博客的作者,在他的文章中也详细说明Embedding技术,在58同城房产相关业务和推荐场景中的实际应用 [1] 。
李乾坤,在GitHub博客上也详细描述Embedding技术的原理和它在自然语言处理中的应用。像Word2Vec和GloVe这样的模型,就是通过把单词变成高维的向量,来捕捉单词之间的语义关系 [2] 。
我不是太懂,把它罗列出来,供你参考,相信这门技术在国内也能很快用到其他场景上。
那么,我们是否可以说:这项技术在迭代传统以整合信源为中心的AI搜索引擎呢? 我不知道,至少觉得它具备一定的市场需求。
比如:
前一段时间有篇文章特别火,叫《中文互联网是否会消失》,抛开争议就整体而言,大家认为中文互联网内容并没有迅速消失,相反,中文内容在全球范围内的比例在增长。
根据W3Techs数据,截止到2024年7月,中文内容在全球网站上的使用比例为1.5%,中文和印地语内容的比重都增加了超过10倍(注:W3Techs一家专门提供数据分析的机构)。
这说明什么? 互联网数据并没有消失,我们要特定工具把它给找出来。
国外风险机构Lightspeed,投资完Exa后,分享了一些关于未来智能体网络的想法。他们提到:
最近,一直在思考一个全新的,支持AI智能体的网络基础设施,这种网络会和我们人类用的网络不一样,因为AI智能体和人类需要的东西不同。
为什么需要智能体网络呢?
一,AI智能体要获取最新且准确的信息来完成任务。 虽然现在的大型语言模型能记住很多数据,但,这些数据很快就会过时,而且不容易找到需要的信息。
二,虽然现在有了检索增强生成(Retrieval-augmented generation)技术,它帮助大型语言模型能够处理训练数据之外的信息,但这些通常都是私人或内部的信息。
理想情况下,AI智能体应该能通过API检索整个公共互联网的信息,这就要新的基础设施——也就是智能体网络。
但是,建设这样的网络,面临很多技术和经济上的挑战。现有网络基础设施,主要是为了服务广告商,而不是用户,传统搜索引擎更关注广告点击和展示,这就导致了“SEO”产业兴起。
内容质量并不总是最重要的。
比如:当你搜“精通Go语言的软件工程师”,理想搜索引擎,应该给你工程师的个人网站或社交媒体资料,而不是一些讨论Go语言的网页。
好的搜索引擎应该能理解“实体”的概念,而不只是泛泛地讨论一些话题。所以,AI想要的搜索结果,可能和人类需要的不一样。
AI用的搜索引擎不应该显示广告,应该直接显示结果,不幸的是,现在人类和AI使用的是同样的搜索结果,这种“一刀切”的方式很糟糕。
Exa 的用武之地就在这,它是一个为AI智能体,专门设计的基于嵌入技术的搜索引擎。
它获取并索引网络上的最新内容,并通过一种独特的“链接预测”模型,通过搜索API,把数据提供给基于大型语言模型的应用程序;这个模型被专门调整,以便更好地理解搜索查询并从索引中返回相关链接。
这好比: 当你向图书管理员询问关于某个主题的书时,他不仅迅速找到了与这个主题相关的书,还确保书正是你现在最需要的那一本。
有了 Exa,互联网变得又新又有趣,AI需要一种新的方式来访问信息,它正在执行和设计适用于AI和互联网信源革命的任务。
是不是很有趣?简单讲:它想给AI搜索引擎“洗个脑”,做中间部分,左手深度检索信源后,右手投喂给大语言模型,让它更聪明、更高效。
总结
中国,什么时候有这样的公司?
很快了,值得期待。 最起码,这两位年轻人的创新想法,让人们看到了新的机会点。
参考:
[1]. DataFunTalk. (2020, June 16). Embedding 技术在房产推荐中的应用 . from:https://www.infoq.cn/article/hcii9dfu4aaat8se2id9
[2]. Li, Q. (2022, March 2). Embedding的原理及实践. from:https://qiankunli.github.io/2022/03/02/embedding.html
本文为专栏作者授权创业邦发表,版权归原作者所有。文章系作者个人观点,不代表创业邦立场,转载请联系原作者。如有任何疑问,请联系editor@cyzone.cn。





